Simultaneous Optimisation of Image Quality Improvement and Text Content Extraction from Scanned Documents
Abstract
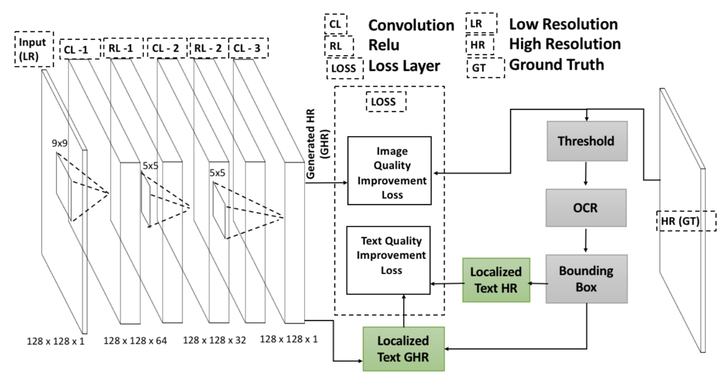
Convolutional neural networks are shown to achieve breakthrough performance for the task of single image super resolution (SISR) for natural images. These state-of-the-art (SOA) networks have been adapted to the task of single text image super resolution and have been shown to boost the optical character recognition (OCR) performance. However, these approaches depend on variations of the standard mean squared error (MSE) loss in order to train the SR network for improving the text image quality which does not guarantee optimal OCR performance. In this paper, we propose to combine the OCR performance into the loss function during network training. This results in the generation of high resolution text images that achieve high OCR performance that is comparable to the ground truth high-resolution text images and surpassing those of the SOA baseline results. We define novel intuitive metrics to capture the improvement in the OCR performance and provide extensive experiments to qualitatively and quantitatively assess improvement in the results of our proposed approach against the SOA baselines on the standard UNLV dataset.
Abhinav Jain
Machine Learning Engineer
My research interests include computer vision, machine learning and deep reinforcement learning.