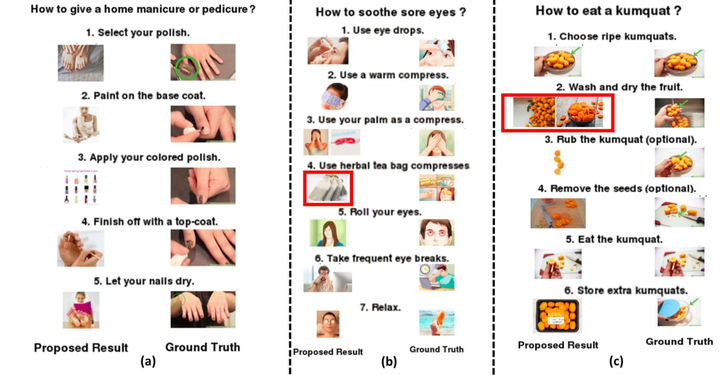
Text is the easiest means to record information and can communicate a fact, argument or logical sequence. But it need not always be the best means for understanding a concept. Images are more evocative than text and invoke lateral thinking, objectivity and global context. By establishing a better balance between the two, comprehension of the textual instructions becomes easier.
We developed a multi-stage framework to provide visual aid for a sequence of text-based instructions in the form of coherent images. For each instruction, the framework mines visualisable phrases consisting of head action verbs and noun phrases (denoting actions, objects and subjects) using standard practices like POS tagging, Dependency parsing and Co-reference Resolution. For each visualisable phrase, an API query is then made to retrieve a set of images from a dataset crawled from sources such as WikiHow, Flickr, Google etc. Across instructions sharing common information in the form of latent/non-latent entities, we maintain coherency using a graph-based matching method that utilises Dijkstra’s algorithm. Phrases and images then together dictate the action being conducted in the instruction.
Abhinav Jain
Machine Learning Engineer
My research interests include computer vision, machine learning and deep reinforcement learning.
Publications
Coherent Visual Description of Textual Instructions
