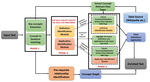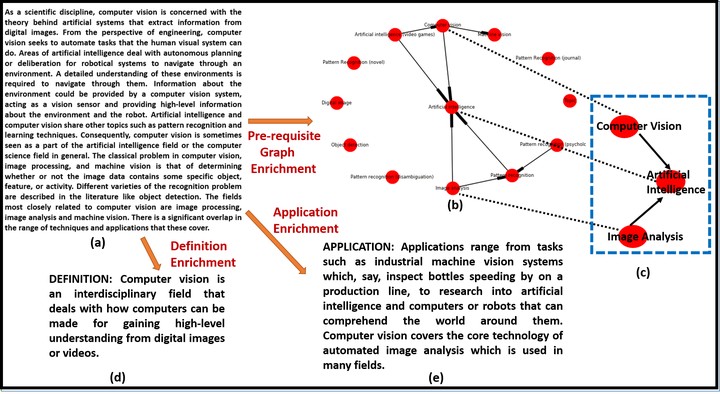
Formal texts such as journal articles are composed of complex terminologies intended to be understood by targeted demographic. In absence of domain knowledge, they tend to be more ambiguous for general readers. To avail a complete semantic understanding of such texts for the readers, we proposed an enrichment system that mitigates the problem of searching for required information through heaps of sources. The system augments given text with required concept definitions, applications and pre-requisite graph.
Pre-requisite graphs show relationships between key concepts in terms of requirement of prior knowledge. They lay out the list of concepts which are crucial to better understand a given query-concept. They have been well studied in cognition and e-learning. However, conventional methods to generate pre-requisite graphs fail to exploit different aspects of inter-concept relationship at once and propose a single hypothesis to probe their behaviour. We analysed a compendium of hypotheses proposed in literature and proposed a robust framework that efficiently combines them using an multi-kernel learning approach.
Our framework extracts key-concepts (technical terms) based on user discretion via a sequence of filtering stages - Linguistic Filtering, BBC Pruning and StackExchange Pruning. After generating the concept dependecy graph, it detects the presence of required information by classifying text associated with each concept into its definition/application using a CNN-LSTM network. Conditionally, the same framework then runs on a data source such as Wikipedia to extract the concept’s missing definition or real-life application.
Abhinav Jain
Machine Learning Engineer
My research interests include computer vision, machine learning and deep reinforcement learning.
Publications
Content Driven Enrichment of Formal Text using Concept Definitions and Applications